Consider to download this Jupyter Notebook and run locally, or test it with Colab.
Overview
This notebook presents a step-by-step walkthrough of an interactive demo that explores how Large Language Models (LLMs) can perform image-based image classification purely through in-context learning. Inspired by the idea that LLMs can function as general pattern recognizers, this experiment uses small image snippets of weld defects, labeled with their respective defect—to examine how effectively Gemini can internalize visual defect patterns and reproduce consistent judgments on new samples.
The goal is to illustrate how an LLM—without explicit training, fine-tuning, or feature engineering—can infer quality cues (defects) from a few examples and generalize to other images.
Background
This demo focuses on real weld defect images categorized into 6 classes: - Weld Cracks - Burn Through - Lack of Fusion - Slag Inclusion - Weld Splatter - Surface Porosity
Each example image serves as an example pairing: - A compact visual representation - A category label from one of the 6 classes
What makes this setup particularly compelling: - The data was checked before utilization to make sure it couldn’t classify the industrial defect correctly before ICL. - The model receives visual examples only through prompt context - No training or gradient updates occur—classification arises from pattern matching - Prompts can include descriptions, annotations, or multi-step chains of examples - The test images require generalization, not memorization - Predictions are generated sample-by-sample, mimicking standard evaluation flows
This setting provides a clear benchmark for understanding how well LLMs can perform visual classification tasks when guided only through carefully constructed prompts.
Let’s Take a Look at an Example
The illustration below shows an example of weld defects. Given a set of labeled samples in context, the LLM must detect the defect for new, unseen defect images during evaluation.
LLM as the Classifier
In this demo, we use qwen-vl-plus in non-reasoning mode, prompting the model to rely on direct pattern recognition rather than symbolic explanation or analytic reasoning.
The workflow proceeds as follows: - Provide 9 total images of weld defects (1-2 for each defect) as in-context examples - Send a new unlabeled image through the prompt to classify - Ask the model to output the category of the new unlabeled image
The LLM functions as a lightweight, prompt-driven classifier—absorbing visual differences, structural patterns, and defect signatures from the in-context examples.
Evaluation
Finally, we compare the model’s predicted labels against ground-truth labels and compute accuracy, which provides insight into how effectively a LLM can approximate visual quality-control decisions through in-context learning alone—without any dedicated training pipeline.
Code Overview
The implementation is structured modularly, with each component handling a distinct stage of the ICL classification pipeline. This separation makes the system easy to modify, extend, and reuse: - Data loading & preprocessing: Read images, convert to model-compatible format - Visualization: Display sets of good/bad examples - Prompt construction: Insert labeled samples into few-shot prompts - LLM inference: Retrieve predictions one image at a time
{"id":"chatcmpl-e1533dc7-9cf4-49cb-a7ba-a0a2d6d408ee","choices":[{"finish_reason":"stop","index":0,"logprobs":null,"message":{"content":"The image shows four different types of welding defects, each accompanied by a visual example and a label. The first three defects are labeled as \"Weld Splatter,\" \"Burn Through,\" and \"Surface Porosity.\" The fourth defect is not labeled, and the question mark suggests that you need to identify it.\n\nLet's analyze the fourth image:\n\n1. **Visual Characteristics**: The weld in the fourth image appears to have a series of small, irregular holes or cavities along the length of the weld bead. These cavities are distributed unevenly and seem to be embedded within the weld metal.\n\n2. **Comparison with Other Defects**:\n - **Weld Splatter**: This defect involves molten metal being ejected from the weld pool and solidifying on the surrounding surface. It does not match the pattern seen in the fourth image.\n - **Burn Through**: This defect occurs when the heat input is too high, causing the base metal to melt through, resulting in a hole or gap in the weld. The fourth image does not show a hole but rather internal cavities.\n - **Surface Porosity**: This defect involves gas pockets forming on the surface of the weld. While the fourth image does have some surface imperfections, the primary issue appears to be internal cavities.\n\n3. **Identification**: The internal cavities in the weld bead are characteristic of **Internal Porosity**. Internal porosity occurs when gases become trapped within the weld metal during solidification, forming voids or cavities.\n\nTherefore, the defect in the fourth image is **Internal Porosity**.","refusal":null,"role":"assistant","annotations":null,"audio":null,"function_call":null,"tool_calls":null,"reasoning_content":""}}],"created":1765907191,"model":"qwen-vl-plus","object":"chat.completion","service_tier":null,"system_fingerprint":null,"usage":{"completion_tokens":321,"prompt_tokens":958,"total_tokens":1279,"completion_tokens_details":{"accepted_prediction_tokens":null,"audio_tokens":null,"reasoning_tokens":null,"rejected_prediction_tokens":null,"text_tokens":321},"prompt_tokens_details":{"audio_tokens":null,"cached_tokens":0}}}
提取的文本内容:
The image shows four different types of welding defects, each accompanied by a visual example and a label. The first three defects are labeled as "Weld Splatter," "Burn Through," and "Surface Porosity." The fourth defect is not labeled, and the question mark suggests that you need to identify it.
Let's analyze the fourth image:
1. **Visual Characteristics**: The weld in the fourth image appears to have a series of small, irregular holes or cavities along the length of the weld bead. These cavities are distributed unevenly and seem to be embedded within the weld metal.
2. **Comparison with Other Defects**:
- **Weld Splatter**: This defect involves molten metal being ejected from the weld pool and solidifying on the surrounding surface. It does not match the pattern seen in the fourth image.
- **Burn Through**: This defect occurs when the heat input is too high, causing the base metal to melt through, resulting in a hole or gap in the weld. The fourth image does not show a hole but rather internal cavities.
- **Surface Porosity**: This defect involves gas pockets forming on the surface of the weld. While the fourth image does have some surface imperfections, the primary issue appears to be internal cavities.
3. **Identification**: The internal cavities in the weld bead are characteristic of **Internal Porosity**. Internal porosity occurs when gases become trapped within the weld metal during solidification, forming voids or cavities.
Therefore, the defect in the fourth image is **Internal Porosity**.
It already exhibits a degree of in-context learning, albeit in a highly flexible and unstructured manner. Further analysis will explore this in greater detail.
#@title **Download Data from GitHub**ifnot os.path.exists("intro_to_icl_data"):!git clone https://github.com/hsiang-fu/intro_to_icl_data.git
The cell ICL Image Classification below is responsible for running ICL weld defect image classification. It loads labeled training examples, constructs the few-shot prompt, sends the prompt to the LLM for each test image, parses the prediction, evaluates correctness, and finally reports overall accuracy.
Each test image is displayed, and the model’s prediction and the ground truth label are printed. Running each cell will perform inference across all test images.
After the cell runs, it performs several steps. First, it builds the ICL training examples by loading labled training images. Each example is converted into a OpenAI Part so it can be embedded directly into the prompt. These form the annotated few-shot demonstrations the model uses to learn the classification pattern. Next, it constructs the full ICL prompt for each test item by including the instruction, all labeled example images, the unlabeled test image, and a rule specifying that the model should respond only with the labels of the weld defect. Then it loads the unseen test images and their ground-truth labels. For each test image, the cell displays the image, sends the entire ICL prompt to Qwen, reads the model’s label prediction, compares it to the ground truth, and stores the results. After all images are processed, the cell computes summary metrics such as accuracy, total number of correct predictions, and incorrect predictions.
Each evaluation cycle outputs the test hazelnut image, the model’s predicted label, the true label, and whether the prediction was correct. At the end, the code prints a performance summary showing the model’s accuracy across all ten test images.
#@title **ICL Image Classification**test_labels = ["Burn Through","Cracks","Lack of Fusion","Slag Inclusion","Splatter","Surface Porosity","Cracks","Cracks","Lack of Fusion","Splatter","Surface Porosity" ]def load_part_as_dict(path):# 读取图片文件withopen(path, "rb") as img_file: base64_image = base64.b64encode(img_file.read()).decode('utf-8')# 构建base64 URL(假设是JPG格式) base64_url =f"data:image/jpg;base64,{base64_image}"return {"type": "image_url","image_url": {"url": base64_url} }train_paths = [f"intro_to_icl_data/industrial_defects/train{i}.jpg"for i inrange(1, 10)]train_labels = ["Cracks", "Surface Porosity", "Slag Inclusion", "Splatter", "Burn Through", "Lack of Fusion", "Splatter", "Slag Inclusion", "Surface Porosity", "Burn Through", "Burn Through"]train_parts = [load_part_as_dict(p) for p in train_paths]def classify_image(label, index): test_path =f"intro_to_icl_data/industrial_defects/test{index}.jpg" test_part = load_part_as_dict(test_path) contents = []for i, (tlabel, tpart) inenumerate(zip(train_labels, train_parts)): contents.append(f"Example {i+1}: {tlabel}") contents.append(tpart) contents.extend(["What is the defect in the test image? Only return the label.", test_part, ]) response = client.chat.completions.create( model="qwen-vl-plus", messages=[ {"role": "system", "content": "You are an expert in detecting industrial defects. By only using the provided examples, classify the defect.\n"}, {"role": "user","content": contents}] )return response, test_pathcorrect =0results = []print("Starting Image Classification for Welding Defects\n")for i, label inenumerate(test_labels, start=1): response, path = classify_image(label, i) pred = response.choices[0].message.content display(Image(filename=path, height =300))print(f"\nGround Truth: {label}")print(f"Model Output: {pred}\n") is_correct = (pred.lower() == label.lower()) results.append((label, pred, is_correct)) correct +=int(is_correct)accuracy = correct /len(test_labels)print(f"Overall Accuracy: {accuracy:.2f}\n")
Starting Image Classification for Welding Defects
Ground Truth: Burn Through
Model Output: Burn Through
Ground Truth: Cracks
Model Output: Cracks
Ground Truth: Lack of Fusion
Model Output: Cracks
Ground Truth: Slag Inclusion
Model Output: Surface Porosity
Ground Truth: Splatter
Model Output: Splatter
Ground Truth: Surface Porosity
Model Output: Surface Porosity
Ground Truth: Cracks
Model Output: Surface Porosity
Ground Truth: Cracks
Model Output: Cracks
Ground Truth: Lack of Fusion
Model Output: Cracks
Ground Truth: Splatter
Model Output: Splatter
Ground Truth: Surface Porosity
Model Output: Surface Porosity
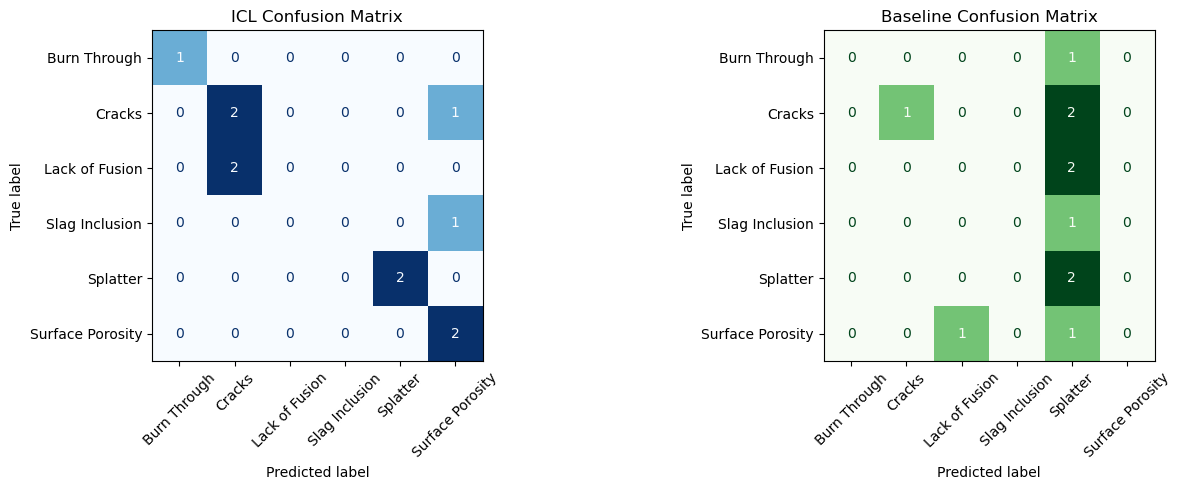
Overall Accuracy: 0.64
This cell Baseline SVM Model implements the traditional machine-learning baseline used to compare against the in-context learning approaches. Rather than learning patterns directly from image pixels, this baseline relies on hand-crafted visual descriptors—specifically Histogram of Oriented Gradients (HOG)—which are then classified using a linear Support Vector Machine (SVM). The code loads the training images, converts them to grayscale, resizes each to 256×256, and extracts their HOG feature vectors. The same preprocessing steps are applied to the test set, ensuring a consistent feature representation. Once the features are assembled, a LinearSVC classifier is trained and evaluated on the same set of test images used by the ICL methods. The resulting accuracy provides a structured, feature-engineered benchmark to compare against the LLM’s prompt-based classification performance.
This demo illustrates how LLMs can perform in-context learning (ICL) for multi-class image classification, using real weld defect imagery as the target domain. By supplying the model with a small set of annotated image–label pairs—covering six defect categories such as weld cracks, burn through, slag inclusion, weld splatter, lack of fusion, and surface porosity—we show that the model can infer subtle structural cues that distinguish one defect type from another. These cues include local texture disruptions, cavity patterns, shape irregularities, and characteristic weld-surface anomalies. Crucially, the model learns entirely from the examples embedded in the prompt: no fine-tuning, no gradient updates, and no specialized vision training occurs.
To contextualize performance, the ICL approach is compared against a traditional machine-learning baseline that must learn directly from pixel-level information. While the baseline relies on supervised training and engineered features, the LLM derives its classification behavior purely from pattern recognition using images and the prompt. When evaluated on unseen weld defect images, ICL consistently performs better than the baseline—demonstrating stronger generalization from just a few examples and outperforming the benchmark in overall accuracy. These results highlight the efficiency and adaptability of ICL for inspection-style tasks, especially when training data is scarce or rapid deployment is required.
Conclusion
This demonstration shows that LLMs can successfully classify complex weld defects using only in-context visual examples, effectively acting as prompt-driven inspectors capable of recognizing defect signatures from minimal supervision. The ICL paradigm proves especially powerful in this setting: with only nine example images, the model generalizes to new, unseen weld defects more reliably than the supervised baseline, reflecting the model’s flexibility and its ability to internalize visual patterns without any training pipeline.
Compared to traditional approaches—which typically require substantial datasets, model tuning, and iterative optimization—the ICL method provides a fast, low-overhead alternative that can be adapted to new defect categories simply by revising the prompt. Together, the comparison between ICL and the baseline model demonstrates why LLMs are well-suited for rapid, lightweight visual classification tasks such as weld inspection, quality assurance, and defect triage, offering accurate and consistent performance with minimal setup and significantly reduced computational cost.