Requirement already satisfied: numpy in /opt/anaconda3/lib/python3.12/site-packages (1.26.4)
Requirement already satisfied: matplotlib in /opt/anaconda3/lib/python3.12/site-packages (3.9.2)
Requirement already satisfied: contourpy>=1.0.1 in /opt/anaconda3/lib/python3.12/site-packages (from matplotlib) (1.2.0)
Requirement already satisfied: cycler>=0.10 in /opt/anaconda3/lib/python3.12/site-packages (from matplotlib) (0.11.0)
Requirement already satisfied: fonttools>=4.22.0 in /opt/anaconda3/lib/python3.12/site-packages (from matplotlib) (4.51.0)
Requirement already satisfied: kiwisolver>=1.3.1 in /opt/anaconda3/lib/python3.12/site-packages (from matplotlib) (1.4.4)
Requirement already satisfied: numpy>=1.23 in /opt/anaconda3/lib/python3.12/site-packages (from matplotlib) (1.26.4)
Requirement already satisfied: packaging>=20.0 in /opt/anaconda3/lib/python3.12/site-packages (from matplotlib) (24.1)
Requirement already satisfied: pillow>=8 in /opt/anaconda3/lib/python3.12/site-packages (from matplotlib) (10.4.0)
Requirement already satisfied: pyparsing>=2.3.1 in /opt/anaconda3/lib/python3.12/site-packages (from matplotlib) (3.1.2)
Requirement already satisfied: python-dateutil>=2.7 in /opt/anaconda3/lib/python3.12/site-packages (from matplotlib) (2.9.0.post0)
Requirement already satisfied: six>=1.5 in /opt/anaconda3/lib/python3.12/site-packages (from python-dateutil>=2.7->matplotlib) (1.16.0)
Requirement already satisfied: pandas in /opt/anaconda3/lib/python3.12/site-packages (2.2.2)
Requirement already satisfied: numpy>=1.26.0 in /opt/anaconda3/lib/python3.12/site-packages (from pandas) (1.26.4)
Requirement already satisfied: python-dateutil>=2.8.2 in /opt/anaconda3/lib/python3.12/site-packages (from pandas) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in /opt/anaconda3/lib/python3.12/site-packages (from pandas) (2024.1)
Requirement already satisfied: tzdata>=2022.7 in /opt/anaconda3/lib/python3.12/site-packages (from pandas) (2023.3)
Requirement already satisfied: six>=1.5 in /opt/anaconda3/lib/python3.12/site-packages (from python-dateutil>=2.8.2->pandas) (1.16.0)
Requirement already satisfied: seaborn in /opt/anaconda3/lib/python3.12/site-packages (0.13.2)
Requirement already satisfied: numpy!=1.24.0,>=1.20 in /opt/anaconda3/lib/python3.12/site-packages (from seaborn) (1.26.4)
Requirement already satisfied: pandas>=1.2 in /opt/anaconda3/lib/python3.12/site-packages (from seaborn) (2.2.2)
Requirement already satisfied: matplotlib!=3.6.1,>=3.4 in /opt/anaconda3/lib/python3.12/site-packages (from seaborn) (3.9.2)
Requirement already satisfied: contourpy>=1.0.1 in /opt/anaconda3/lib/python3.12/site-packages (from matplotlib!=3.6.1,>=3.4->seaborn) (1.2.0)
Requirement already satisfied: cycler>=0.10 in /opt/anaconda3/lib/python3.12/site-packages (from matplotlib!=3.6.1,>=3.4->seaborn) (0.11.0)
Requirement already satisfied: fonttools>=4.22.0 in /opt/anaconda3/lib/python3.12/site-packages (from matplotlib!=3.6.1,>=3.4->seaborn) (4.51.0)
Requirement already satisfied: kiwisolver>=1.3.1 in /opt/anaconda3/lib/python3.12/site-packages (from matplotlib!=3.6.1,>=3.4->seaborn) (1.4.4)
Requirement already satisfied: packaging>=20.0 in /opt/anaconda3/lib/python3.12/site-packages (from matplotlib!=3.6.1,>=3.4->seaborn) (24.1)
Requirement already satisfied: pillow>=8 in /opt/anaconda3/lib/python3.12/site-packages (from matplotlib!=3.6.1,>=3.4->seaborn) (10.4.0)
Requirement already satisfied: pyparsing>=2.3.1 in /opt/anaconda3/lib/python3.12/site-packages (from matplotlib!=3.6.1,>=3.4->seaborn) (3.1.2)
Requirement already satisfied: python-dateutil>=2.7 in /opt/anaconda3/lib/python3.12/site-packages (from matplotlib!=3.6.1,>=3.4->seaborn) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in /opt/anaconda3/lib/python3.12/site-packages (from pandas>=1.2->seaborn) (2024.1)
Requirement already satisfied: tzdata>=2022.7 in /opt/anaconda3/lib/python3.12/site-packages (from pandas>=1.2->seaborn) (2023.3)
Requirement already satisfied: six>=1.5 in /opt/anaconda3/lib/python3.12/site-packages (from python-dateutil>=2.7->matplotlib!=3.6.1,>=3.4->seaborn) (1.16.0)
Requirement already satisfied: scikit-learn in /opt/anaconda3/lib/python3.12/site-packages (1.5.1)
Requirement already satisfied: numpy>=1.19.5 in /opt/anaconda3/lib/python3.12/site-packages (from scikit-learn) (1.26.4)
Requirement already satisfied: scipy>=1.6.0 in /opt/anaconda3/lib/python3.12/site-packages (from scikit-learn) (1.13.1)
Requirement already satisfied: joblib>=1.2.0 in /opt/anaconda3/lib/python3.12/site-packages (from scikit-learn) (1.4.2)
Requirement already satisfied: threadpoolctl>=3.1.0 in /opt/anaconda3/lib/python3.12/site-packages (from scikit-learn) (3.5.0)
I. Motivation
First of all, why use Gaussian Process to do regression? Or even, what is regression? Regression is a common machine learning task that can be described as Given some observed data points (training dataset), finding a function that represents the dataset as close as possible, then using the function to make predictions at new data points. Regression can be conducted with polynomials, and it’s common there is more than one possible function that fits the observed data. Besides getting predictions by the function, we also want to know how certain these predictions are. Moreover, quantifying uncertainty is super valuable to achieve an efficient learning process. The areas with the least certainty should be explored more.
In a word, GP can be used to make predictions at new data points and can tell us how certain these predictions are.
A random variable \(X\) is said to be normally distributed with mean \(\mu\) and variance \(\sigma^2\) if its probability density function (PDF) is \[ P_X(x) = \frac{1}{\sqrt{2 \pi} \sigma} exp{\left(-\frac{{\left(x - \mu \right)}^{2}}{2 \sigma^{2}}\right)}\]
Here, \(X\) represents random variables and \(x\) is the real argument. The Gaussian or Normal distribution of \(X\) is usually represented by $ P(x) ~ (, ^2)$.
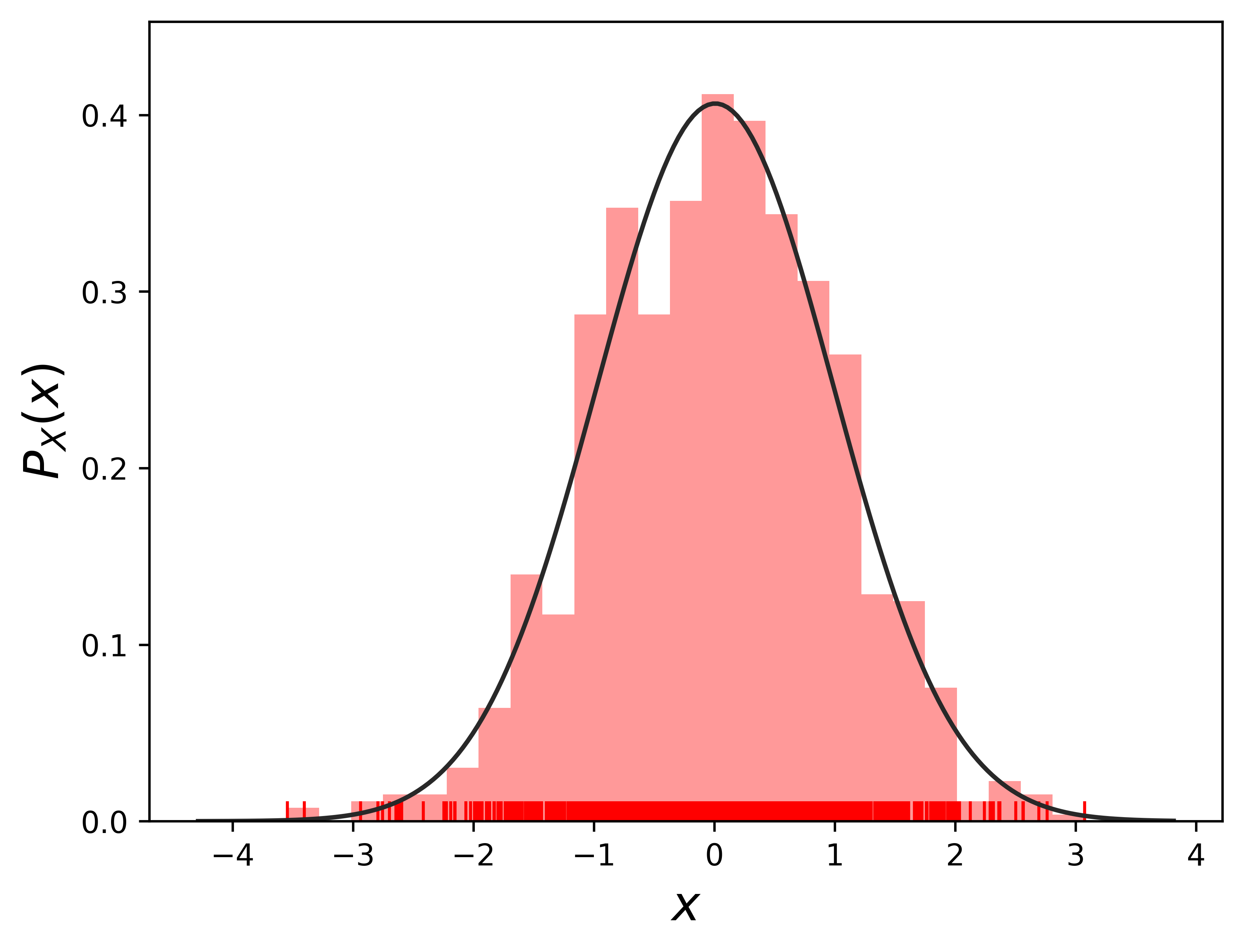
A \(1-D\) Gaussian PDF is plotted below. We generate n number random sample points from a \(1-D\) Gaussian distribution on x axis.
from __future__ import divisionimport numpy as npimport matplotlib.pyplot as pltimport pandas as pdimport seaborn as sns
from scipy.stats import norm# Plot 1-D gaussiann =1# n number of independent 1-D gaussianm=1000# m points in 1-D gaussianf_random = np.random.normal(size=(n, m))# more information about 'size': https://www.sharpsightlabs.com/blog/numpy-random-normal/#print(f_random.shape)for i inrange(n):#sns.distplot(f_random[i], hist=True, rug=True, vertical=True, color="orange") sns.distplot(f_random[i], hist=True, rug=True, fit=norm, kde=False, color="r", vertical=False)#plt.title('1000 random samples by a 1-D Gaussian')plt.xlabel(r'$x$', fontsize =16)plt.ylabel(r'$P_X(x)$', fontsize =16)# plt.show()# plt.savefig('1d_random.png', bbox_inches='tight', dpi=600)plt.savefig('1d_random')
/var/folders/nl/7_2jcxd12wb5z06jvsj1v4240000gn/T/ipykernel_52251/1811352357.py:12: UserWarning:
`distplot` is a deprecated function and will be removed in seaborn v0.14.0.
Please adapt your code to use either `displot` (a figure-level function with
similar flexibility) or `histplot` (an axes-level function for histograms).
For a guide to updating your code to use the new functions, please see
https://gist.github.com/mwaskom/de44147ed2974457ad6372750bbe5751
sns.distplot(f_random[i], hist=True, rug=True, fit=norm, kde=False, color="r", vertical=False)
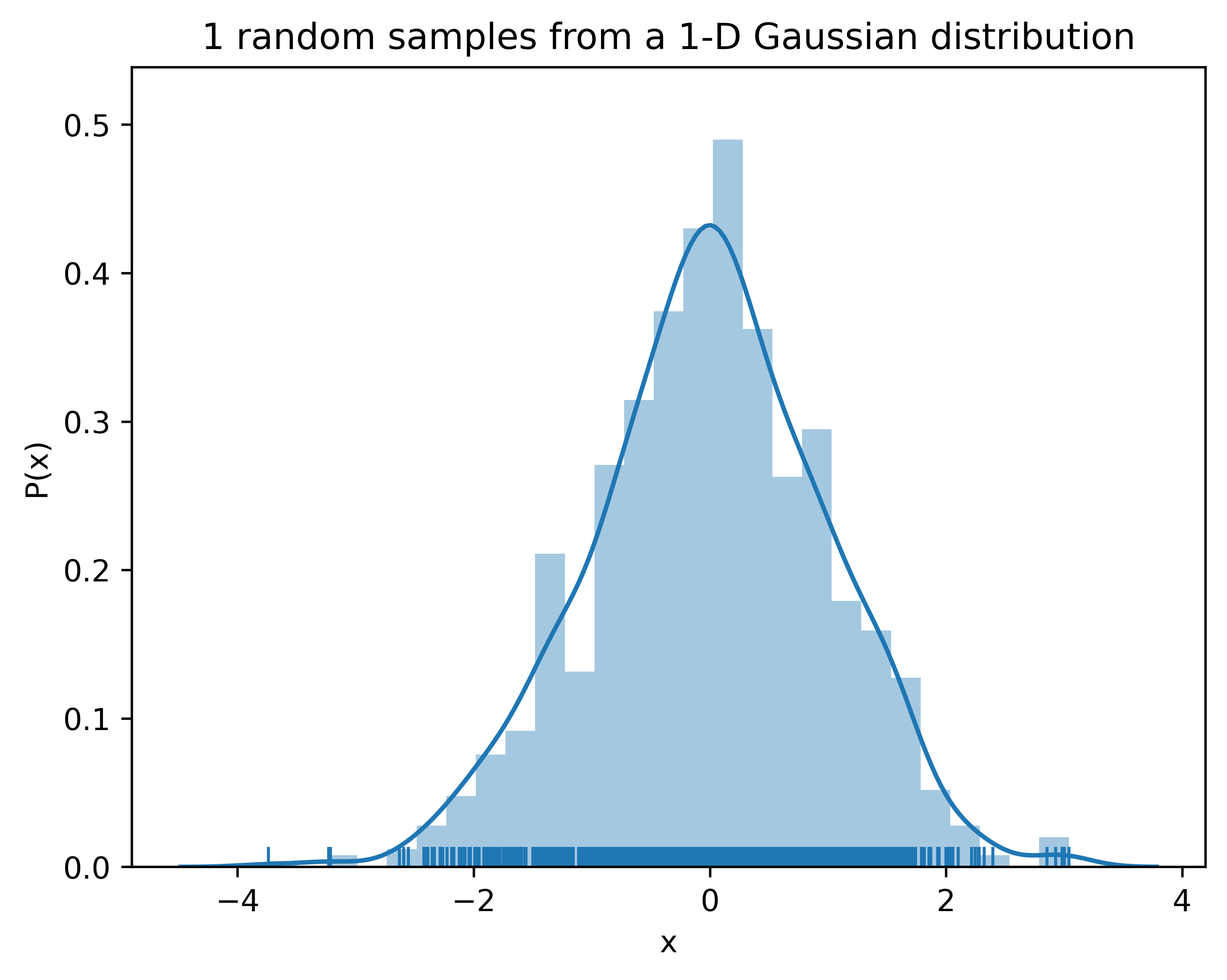
# Plot 1-D gaussiann =1# n number of independent 1-D gaussianm=1000# m points in 1-D gaussianf_random = np.random.normal(size=(n, m))# more information about 'size': https://www.sharpsightlabs.com/blog/numpy-random-normal/#print(f_random.shape)for i inrange(n):#sns.distplot(f_random[i], hist=True, rug=True, vertical=True, color="orange") sns.distplot(f_random[i], hist=True, rug=True)plt.title('1 random samples from a 1-D Gaussian distribution')plt.xlabel('x')plt.ylabel('P(x)')plt.show()
/var/folders/nl/7_2jcxd12wb5z06jvsj1v4240000gn/T/ipykernel_52251/3710904256.py:10: UserWarning:
`distplot` is a deprecated function and will be removed in seaborn v0.14.0.
Please adapt your code to use either `displot` (a figure-level function with
similar flexibility) or `histplot` (an axes-level function for histograms).
For a guide to updating your code to use the new functions, please see
https://gist.github.com/mwaskom/de44147ed2974457ad6372750bbe5751
sns.distplot(f_random[i], hist=True, rug=True)
We generated data points that follow the normal distribution. On the other hand, we can model data points, assume these points are Gaussian, model as a function, and do regression using it. As shown above, a kernel density and histogram of the generated points were estimated. The kernel density estimation looks a normal distribution due to there are plenty (m=1000) observation points to get this Gaussian looking PDF. In regression, even we don’t have that many observation data, we can model the data as a function that follows a normal distribution if we assume a Gaussian prior.
We have a random generated dataset in \(1-D\)\(\mathbf{D}=[x^{(1)}, x^{(2)}, \ldots, x^{(m)}]\). We sampled the generated dataset and got a \(1-D\)Gaussian bell curve.
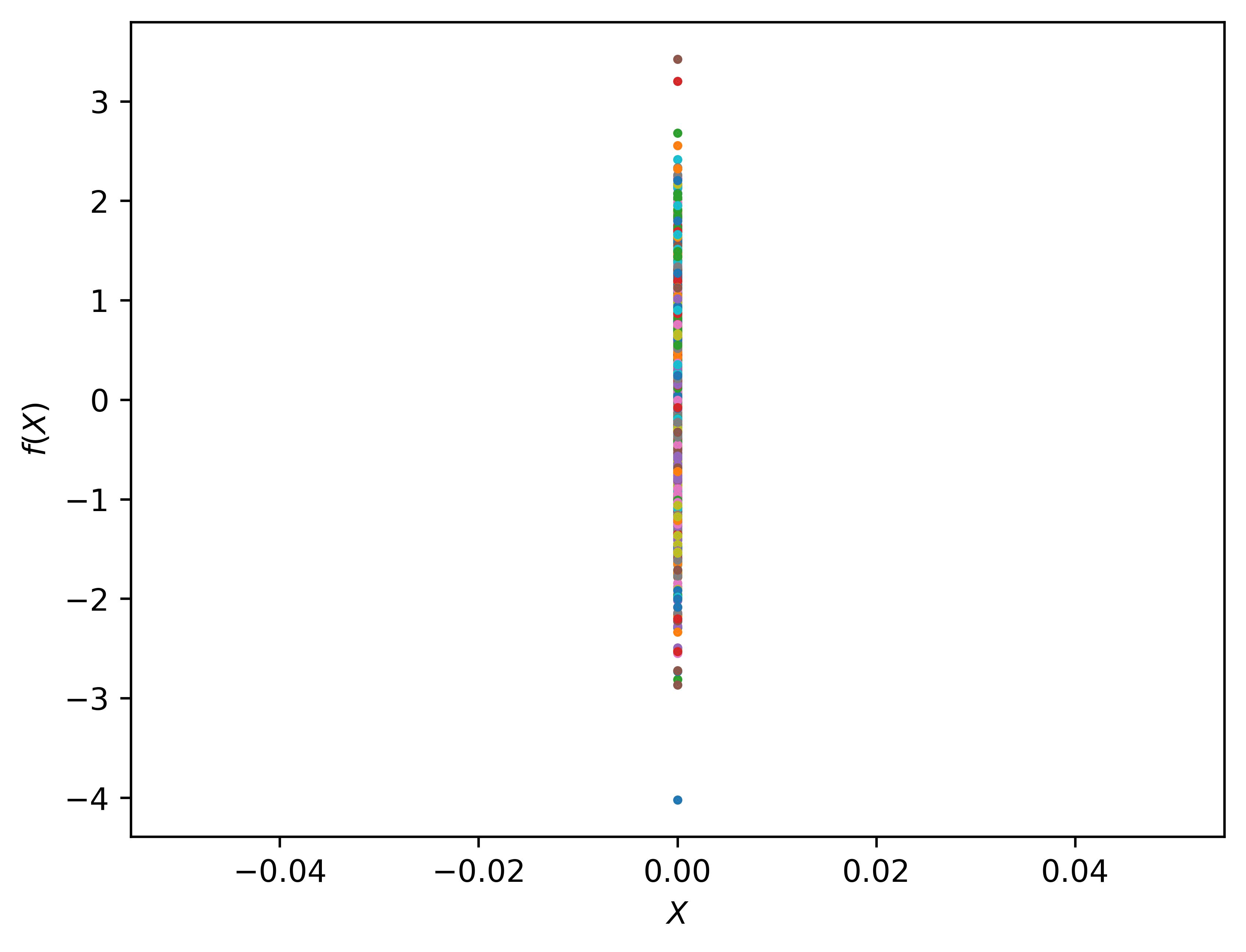
Now, if we project all points \([x^{(1)}, x^{(2)}, \ldots, x^{(m)}]\) on the x-axis to another space. In this space, We treat all points \([x^{(1)}, x^{(2)}, \ldots, x^{(m)}]\) as a vector \(X_1\), and plot \(X_1\) on the new \(X\) axis at \(X = 0\).
n =1# n number of independent 1-D gaussianm=1000# m points in 1-D gaussianf_random = np.random.normal(size=(n, m))Xshow = np.linspace(0, 1, n).reshape(-1,1) # n number test points in the range of (0, 1)plt.clf()plt.plot(Xshow, f_random, 'o', linewidth=1, markersize=1, markeredgewidth=2)plt.xlabel('$X$')plt.ylabel('$f(X)$')plt.show()
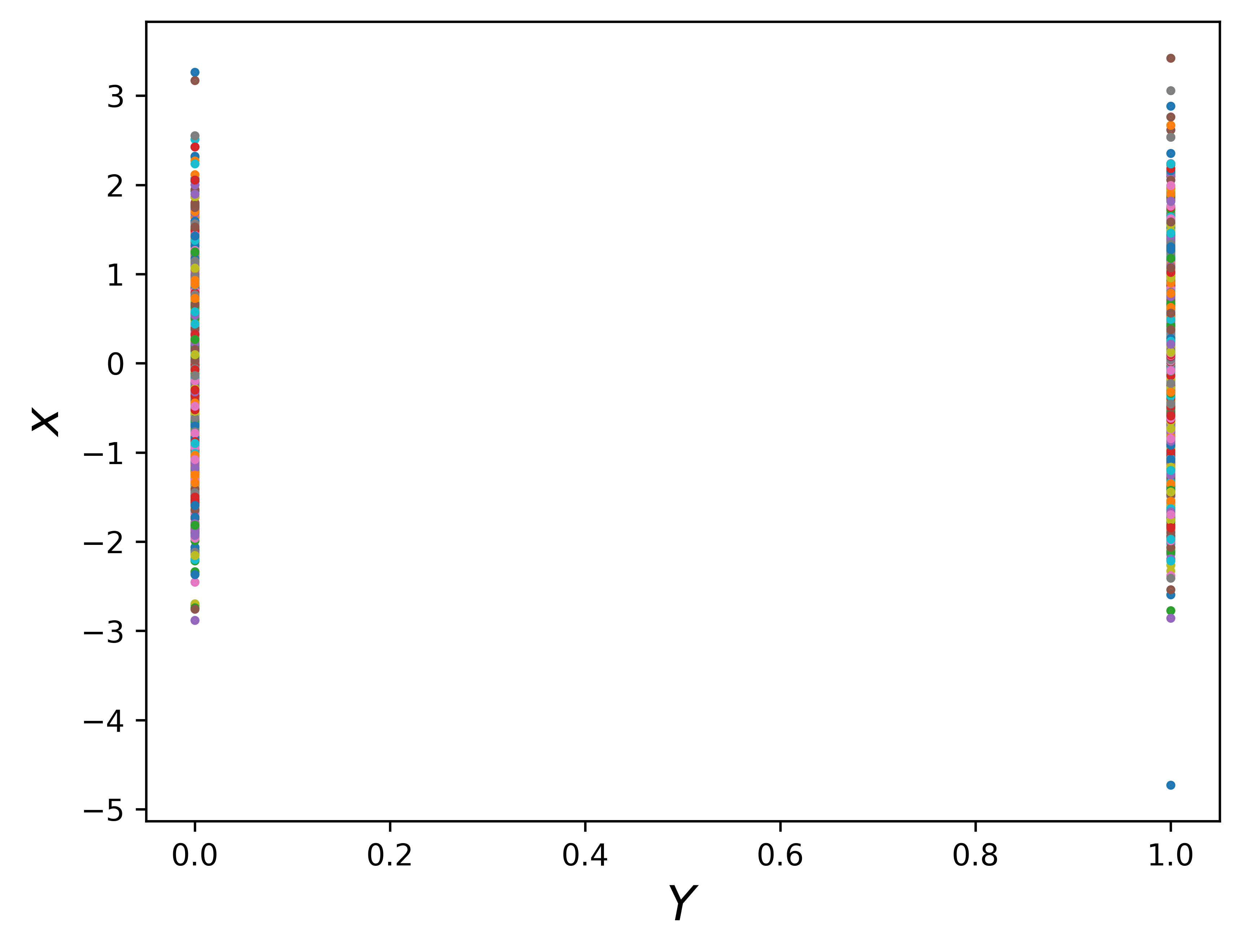
It’s clear that the vector \(X_1\) is Gaussian. It looks like we did nothing but vertically plot the vector points \(X_1\). Next, we can plot multiple independent Gaussian in the \(X-Y\) coordinates. For example, put vector \(X_1\) at at \(X = 0\) and another vector \(X_2\) at at \(X = 1\).
n =2m =1000f_random = np.random.normal(size=(n, m))Xshow = np.linspace(0, 1, n).reshape(-1,1) # n number test points in the range of (0, 1)plt.clf()plt.plot(Xshow, f_random, 'o', linewidth=1, markersize=1, markeredgewidth=2)plt.xlabel(r'$Y$', fontsize =16)plt.ylabel(r'$x$', fontsize =16)# plt.show()# plt.savefig('1d_random.png', bbox_inches='tight', dpi=600)plt.savefig('2gaussian')
Keep in mind that both vecotr \(X_1\) and \(X_2\) are Gaussian.
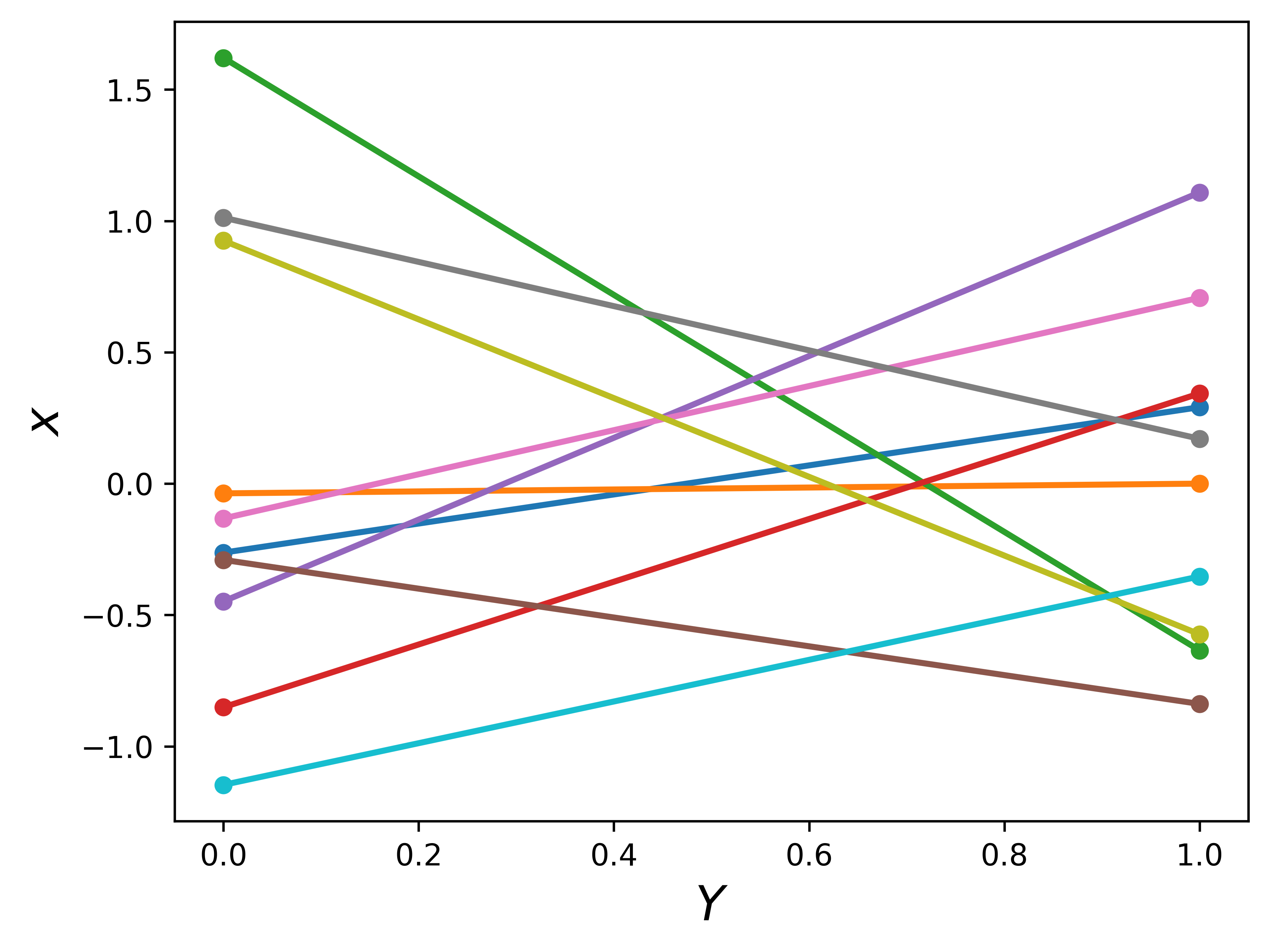
Let’s do something interesting. Let’s connect points of \(X_1\) and \(X_2\) by lines. For now, we only generate 10 random points for \(X_1\) and \(X_2\), and then join them up as 10 lines. Keep in mind, these random generated 10 points are Gaussian.
n =2m =10f_random = np.random.normal(size=(n, m))Xshow = np.linspace(0, 1, n).reshape(-1,1) # n number test points in the range of (0, 1)plt.clf()plt.plot(Xshow, f_random, '-o', linewidth=2, markersize=4, markeredgewidth=2)plt.xlabel(r'$Y$', fontsize =16)plt.ylabel(r'$x$', fontsize =16)# plt.show()# plt.savefig('1d_random.png', bbox_inches='tight', dpi=600)plt.savefig('random_x1_x2')
Going back to think about regression. These lines look like functions for each pair of points. On the other hand, the plot also looks like we are sampling the region \([0, 1]\) with 10 linear functions even there are only two points on each line. In the sampling perspective, the \([0, 1]\) domain is our region of interest, i.e. the specific region we do our regression. This sampling looks even more clear if we generate more independent Gaussian and connecting points in order by lines.
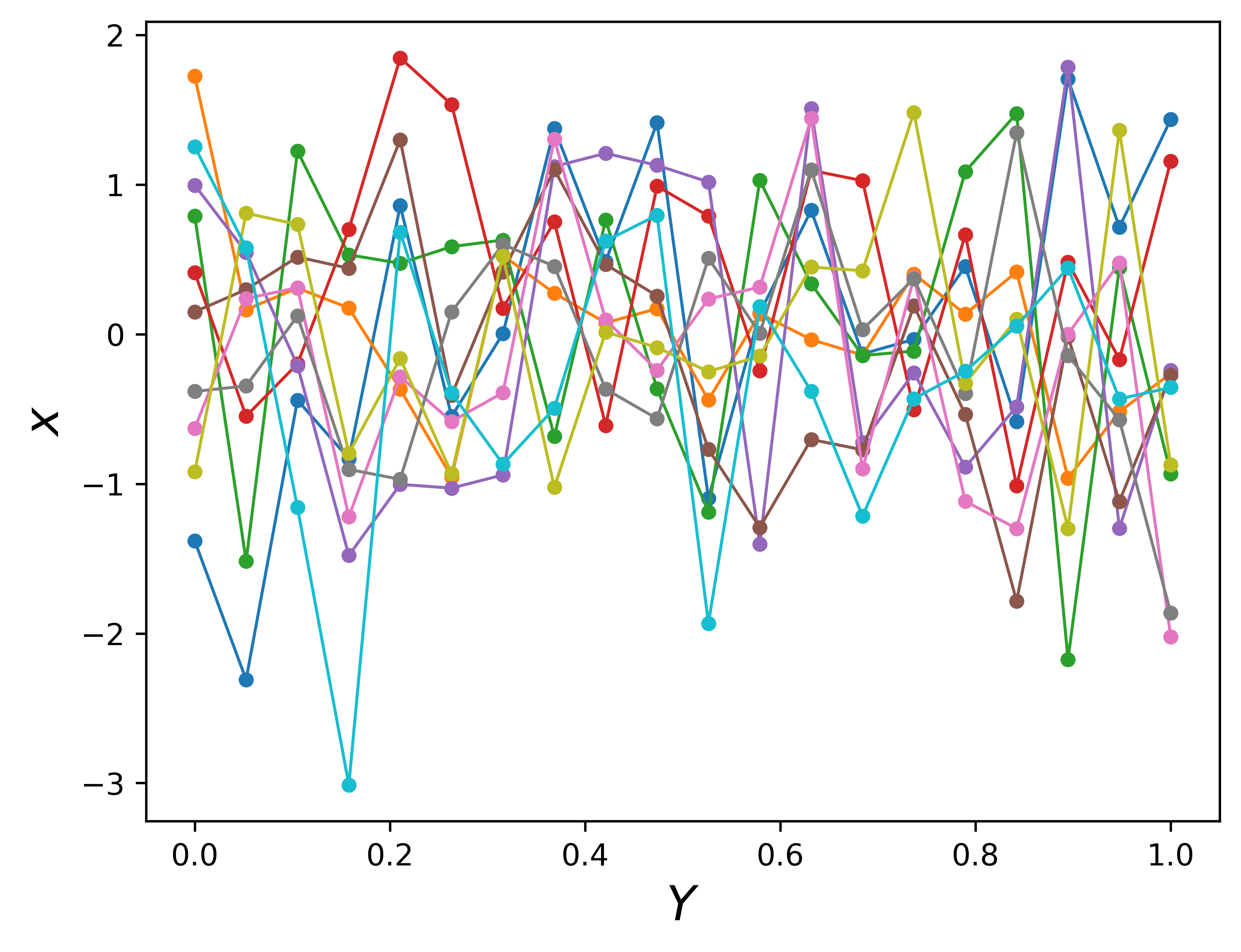
n =20m =10f_random = np.random.normal(size=(n, m))Xshow = np.linspace(0, 1, n).reshape(-1,1) # n number test points in the range of (0, 1)plt.clf()plt.plot(Xshow, f_random, '-o', linewidth=1, markersize=3, markeredgewidth=2)plt.xlabel(r'$Y$', fontsize =16)plt.ylabel(r'$x$', fontsize =16)# plt.show()# plt.savefig('1d_random.png', bbox_inches='tight', dpi=600)plt.savefig('random_x1_x20')
Wait for a second, what we are trying to do by connecting random generated independent Gaussian points? Even these lines look like functions, but they are too noisy. If \(X\) is our input space, these functions are meaningless for the regression task. We can do no prediction by using these functions. The functions should be smoother, meaning input points that are close to each other should have similar values of the function.
Thus, functions by connecting independent Gaussian are not proper for regression, we need Gaussians that correlated to each other. How to describe joint Gaussian? Multivariable Gaussian.
B. Multivariate Normal Distribution (MVN)
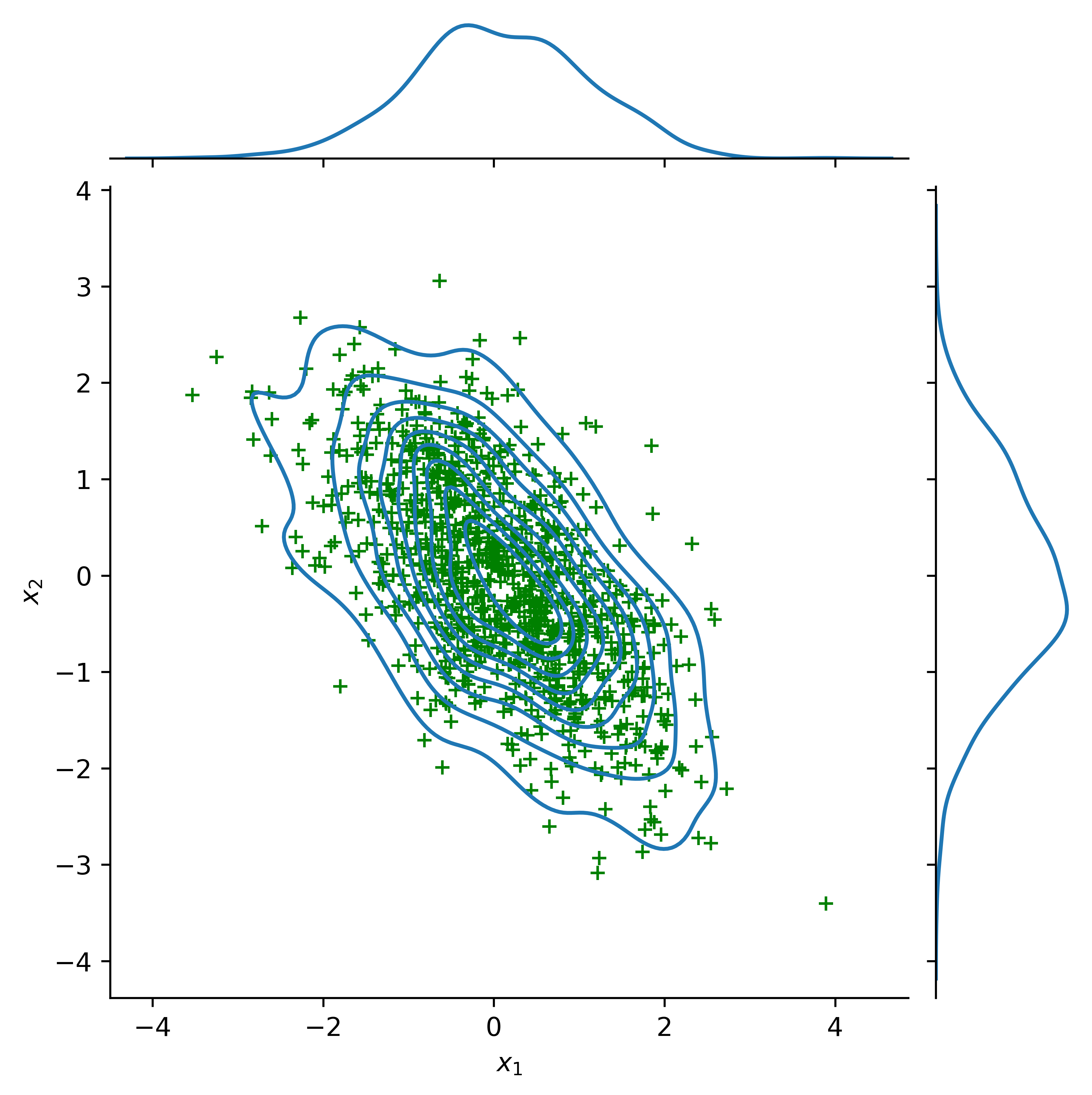
The \(2-D\) gaussian can be visualized as a 3D bell curve with the heights representing probability density. The \(P(x_1, x_2)\) is the joint probability distribution.
Goes to Appendix A if you want to generate image on the left.
Formally, multivariate Gaussian is expressed as [4]
The mean vector\(\mu\) is a 2d vector \((\mu_1, \mu_2)\), which are independent mean of each variable \(x_1\) and \(x_2\).
The covariance matrix of \(2-D\) Gaussian is \(\begin{pmatrix} \sigma^2_1 & \sigma_{12} \\ \sigma_{21} & \sigma^2_2 \end{pmatrix}\). The diagonal terms are independent variances of each variable, \(x_1\) and \(x_2\). The offdiagonal terms represents correlations between the two variables. A correlation component represents how much one variable is related to another variable.
A \(2-D\) Gaussian can be expressed as \[ \begin{pmatrix} x_1 \\ x_2 \end{pmatrix} \sim \mathcal{N}\left(\begin{pmatrix} \mu1 \\ \mu_2 \end{pmatrix}, \begin{pmatrix} \sigma^2_1 & \sigma_{12} \\ \sigma_{21} & \sigma^2_2 \end{pmatrix}\right) \sim \mathcal{N}(\mu, \Sigma)\]
When we have an \(N-D\) Gaussian, the covariance matrix \(\Sigma\) is \(N×N\) and its \((i,j)\) element is \(\Sigma_{ij}=cov(y_i,y_j)\). The \(\Sigma\) is a symmetric matrix and stores the pairwise covariances of all the jointly modeled random variables.
Play around with the covariance matrix to see the correlations between the two Gaussians.
import pandas as pdimport seaborn as snsmean, cov = [0., 0.], [(1., -0.6), (-0.6, 1.)]data = np.random.multivariate_normal(mean, cov, 1000)df = pd.DataFrame(data, columns=["x1", "x2"])# Updated parameter names to current seaborn syntaxg = sns.jointplot(x="x1", y="x2", data=df, kind="kde")g.plot_joint(plt.scatter, c="g", s=30, linewidth=1, marker="+")g.set_axis_labels("$x_1$", "$x_2$") # Changed to subscript notationplt.show()
C. Kernels
We want to smooth the sampling functions by defining the covariance functions. Considering the fact that when two vectors are similar, their dot product output value is high. It is very clear to see this in the dot product equation \(A\,B = AB\,cos\theta\), where \(\theta\) is the angle between two vectors. If an algorithm is defined solely in terms of inner products in input space then it can be lifted into feature space by replacing occurrences of those inner products by \(k(x,\ x^\prime)\); we call \(k(\bullet,\bullet)\) a kernel function.
A popular covariance function (aka kernel function) is squared exponential kernal, also called the radial basis function (RBF) kernel or Gaussian kernel, defined as
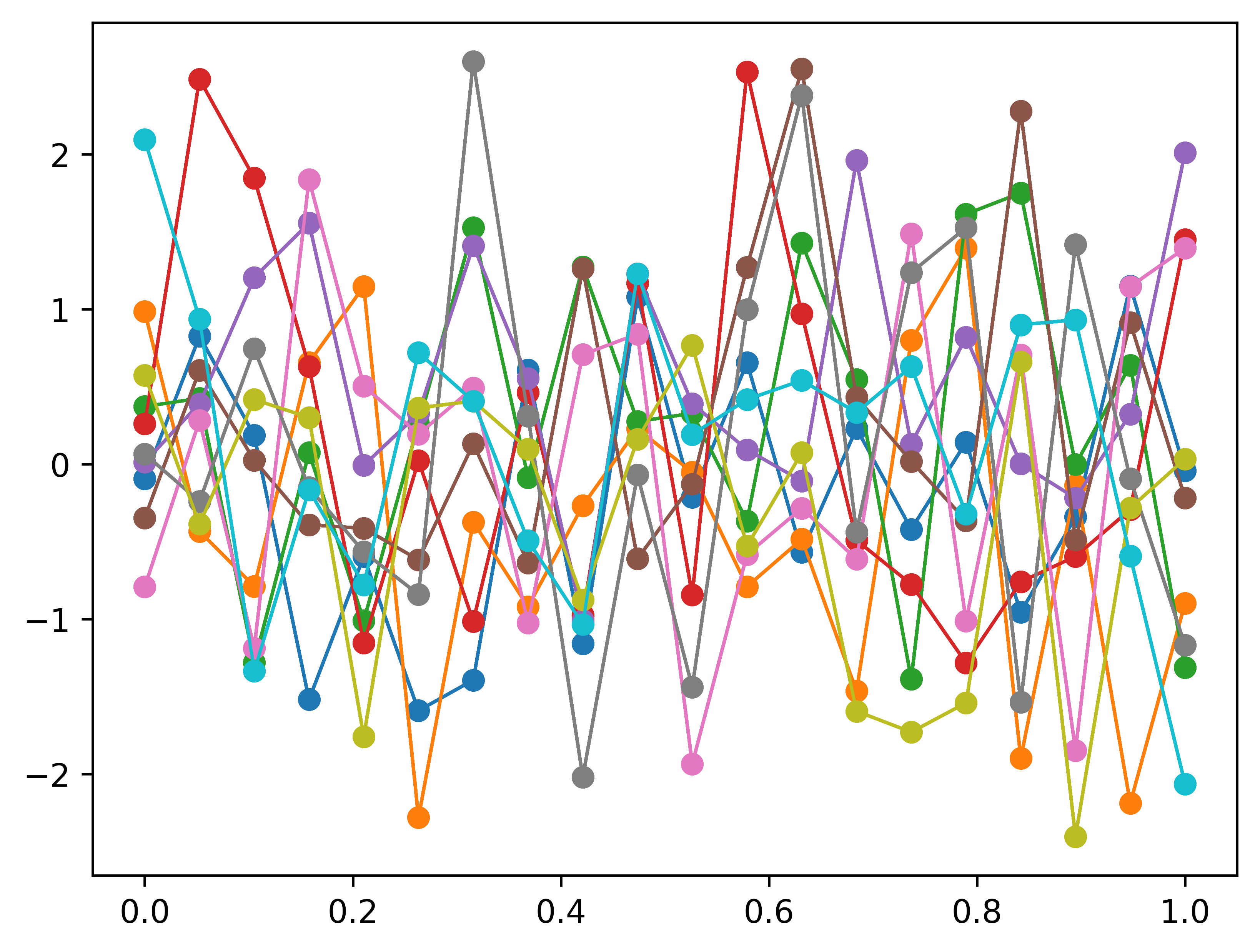
Let’s re-plot 20 independent Gaussian and connecting points in order by lines. Instead of generating 20 independent Gaussian before, we do the plot of a \(20-D\) Gaussian with a identity convariance matrix.
n =20m =10mean = np.zeros(n)cov = np.eye(n)f_prior = np.random.multivariate_normal(mean, cov, m).Tplt.clf()#plt.plot(Xshow, f_prior, '-o')Xshow = np.linspace(0, 1, n).reshape(-1,1) # n number test points in the range of (0, 1)for i inrange(m): plt.plot(Xshow, f_prior, '-o', linewidth=1)# plt.title('10 samples of the 20-D gaussian prior')# plt.show()plt.savefig('20d_gaussian_prior')
We got exactly the same plot as expected. Now let’s kernelizing our funcitons by use the RBF as our convariace.
# Define the kerneldef kernel(a, b): sqdist = np.sum(a**2,axis=1).reshape(-1,1) + np.sum(b**2,1) -2*np.dot(a, b.T)# np.sum( ,axis=1) means adding all elements columnly; .reshap(-1, 1) add one dimension to make (n,) become (n,1)return np.exp(-.5* sqdist)
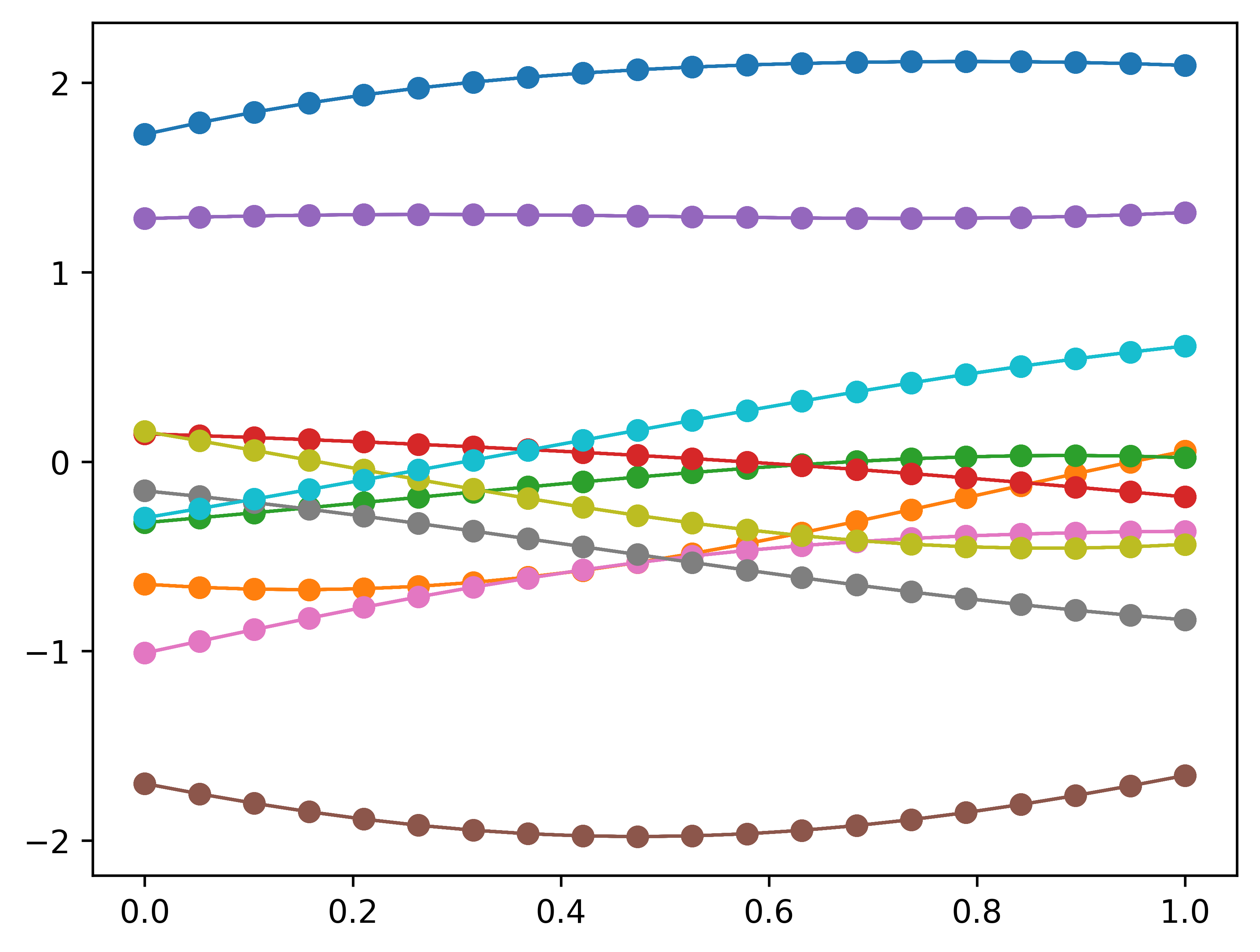
n =20m =10Xshow = np.linspace(0, 1, n).reshape(-1,1) # n number test points in the range of (0, 1)K_ = kernel(Xshow, Xshow) # k(x_star, x_star)mean = np.zeros(n)cov = np.eye(n)f_prior = np.random.multivariate_normal(mean, K_, m).Tplt.clf()Xshow = np.linspace(0, 1, n).reshape(-1,1) # n number test points in the range of (0, 1)for i inrange(m): plt.plot(Xshow, f_prior, '-o', linewidth=1)# plt.title('10 samples of the 20-D gaussian kernelized prior')# plt.show()plt.savefig('20d_gaussian_kernel_prior')
We get much smoother lines and looks even more like functions. When the dimension of Gaussian gets larger, there is no need to connect points. When the dimension become infinity, there is a point represents any possible input. Let’s plot m=200 samples of n=200\(-D\) Gaussian to get a feeling of functions with infinity parameters.
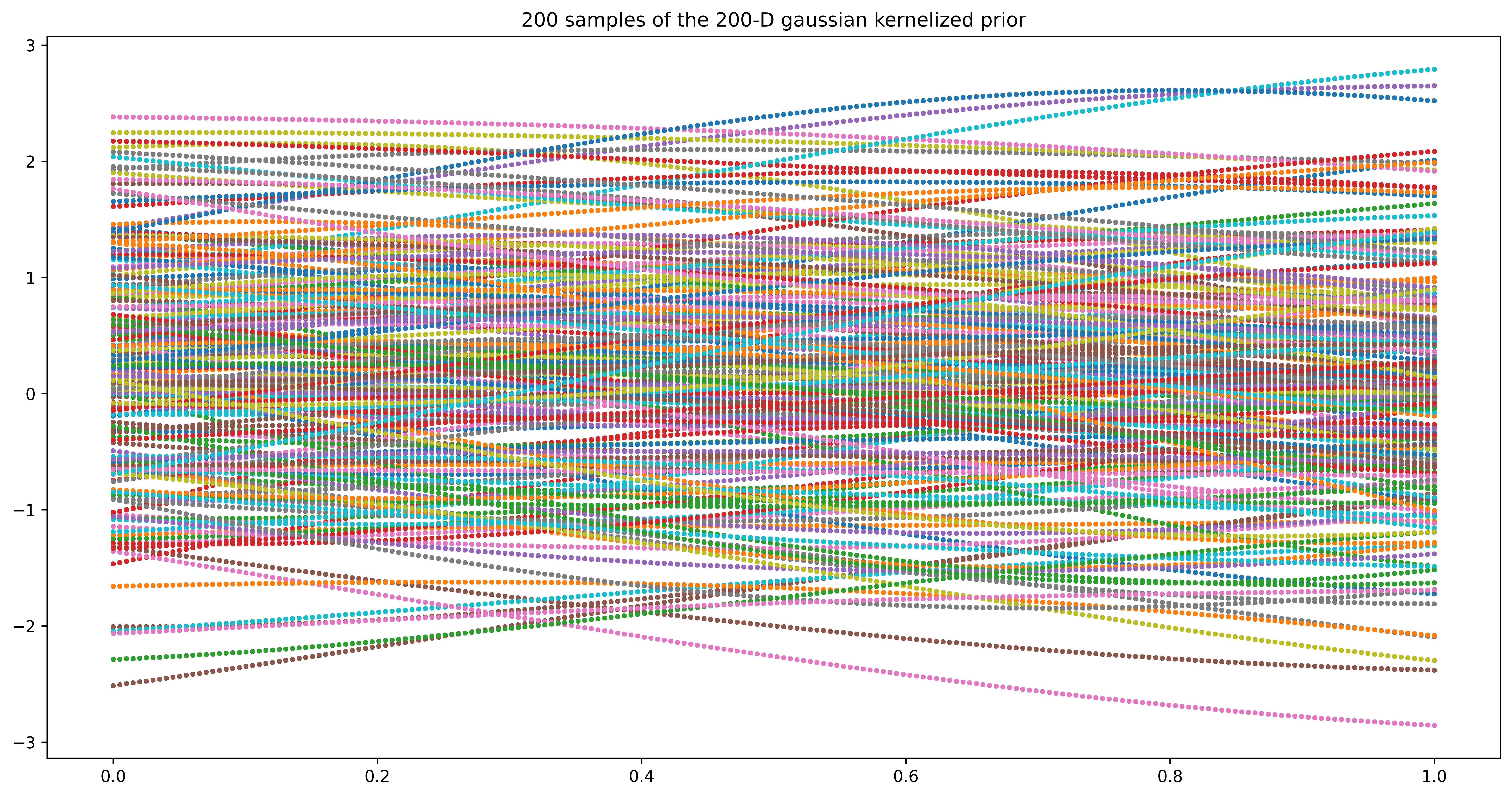
n =200m =200Xshow = np.linspace(0, 1, n).reshape(-1,1)K_ = kernel(Xshow, Xshow) # k(x_star, x_star)mean = np.zeros(n)cov = np.eye(n)f_prior = np.random.multivariate_normal(mean, K_, m).Tplt.clf()#plt.plot(Xshow, f_prior, '-o')Xshow = np.linspace(0, 1, n).reshape(-1,1) # n number test points in the range of (0, 1)plt.figure(figsize=(16,8))for i inrange(m): plt.plot(Xshow, f_prior, 'o', linewidth=1, markersize=2, markeredgewidth=1)plt.title('200 samples of the 200-D gaussian kernelized prior')#plt.axis([0, 1, -3, 3])plt.show()#plt.savefig('priorT.png', bbox_inches='tight', dpi=300)
<Figure size 3840x2880 with 0 Axes>
As we can see above, when we increase the dimension of Gaussian to infinity, we can sample all the possible points in our region of interest.
A great visualization animation of two and four points covariance of the “functions” respectively.
To generate correlated normally distributed random samples, one can first generate uncorrelated samples, and then multiply them by a matrix L such that \(L L^T = K\), where K is the desired covariance matrix. L can be created, for example, by using the Cholesky decomposition of K.
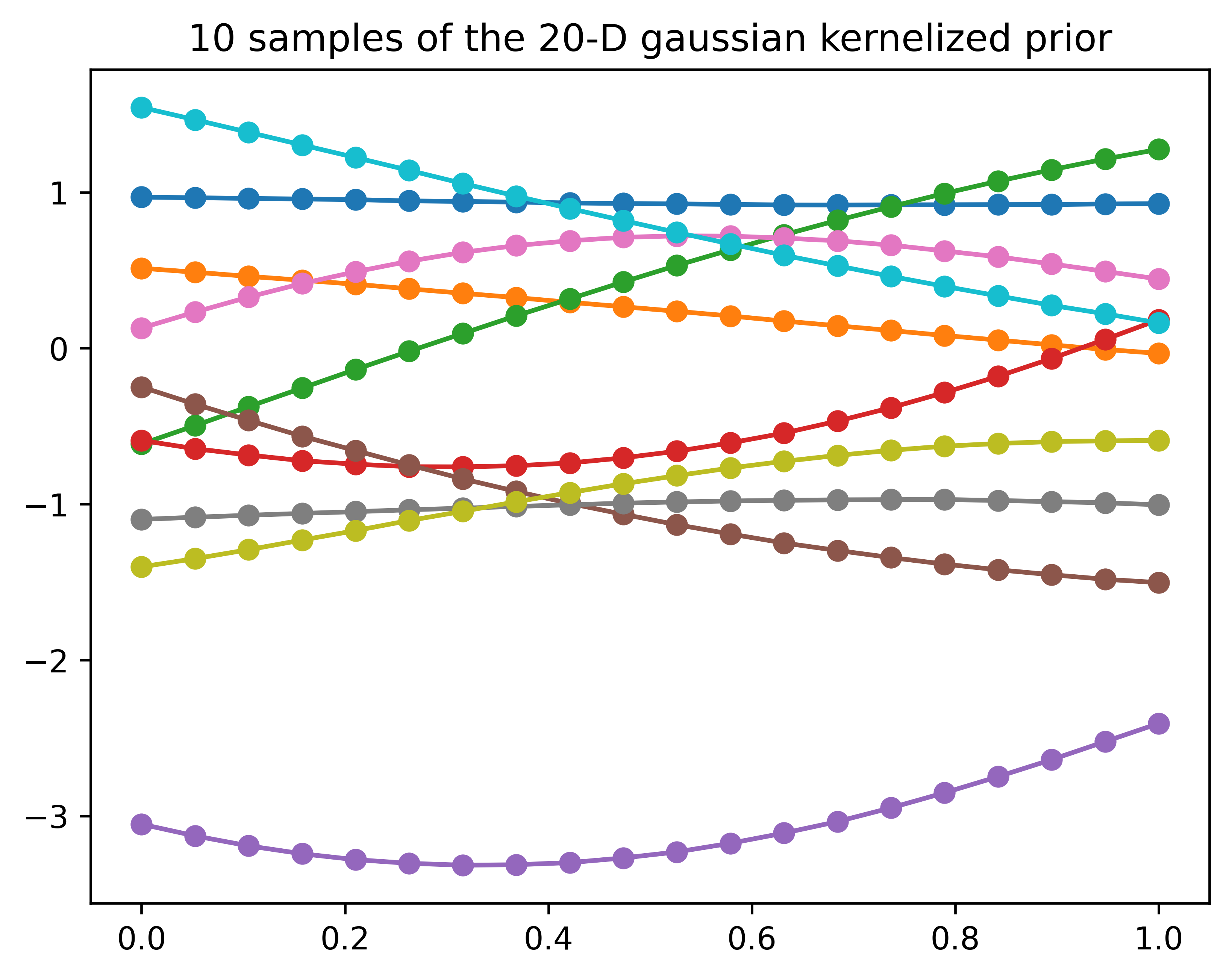
n =20m =10Xshow = np.linspace(0, 1, n).reshape(-1,1) # n number test points in the range of (0, 1)K_ = kernel(Xshow, Xshow)L = np.linalg.cholesky(K_ +1e-6*np.eye(n))f_prior = np.dot(L, np.random.normal(size=(n,m)))plt.clf()plt.plot(Xshow, f_prior, '-o')plt.title('10 samples of the 20-D gaussian kernelized prior')plt.show()
III. Simple Implementation Example
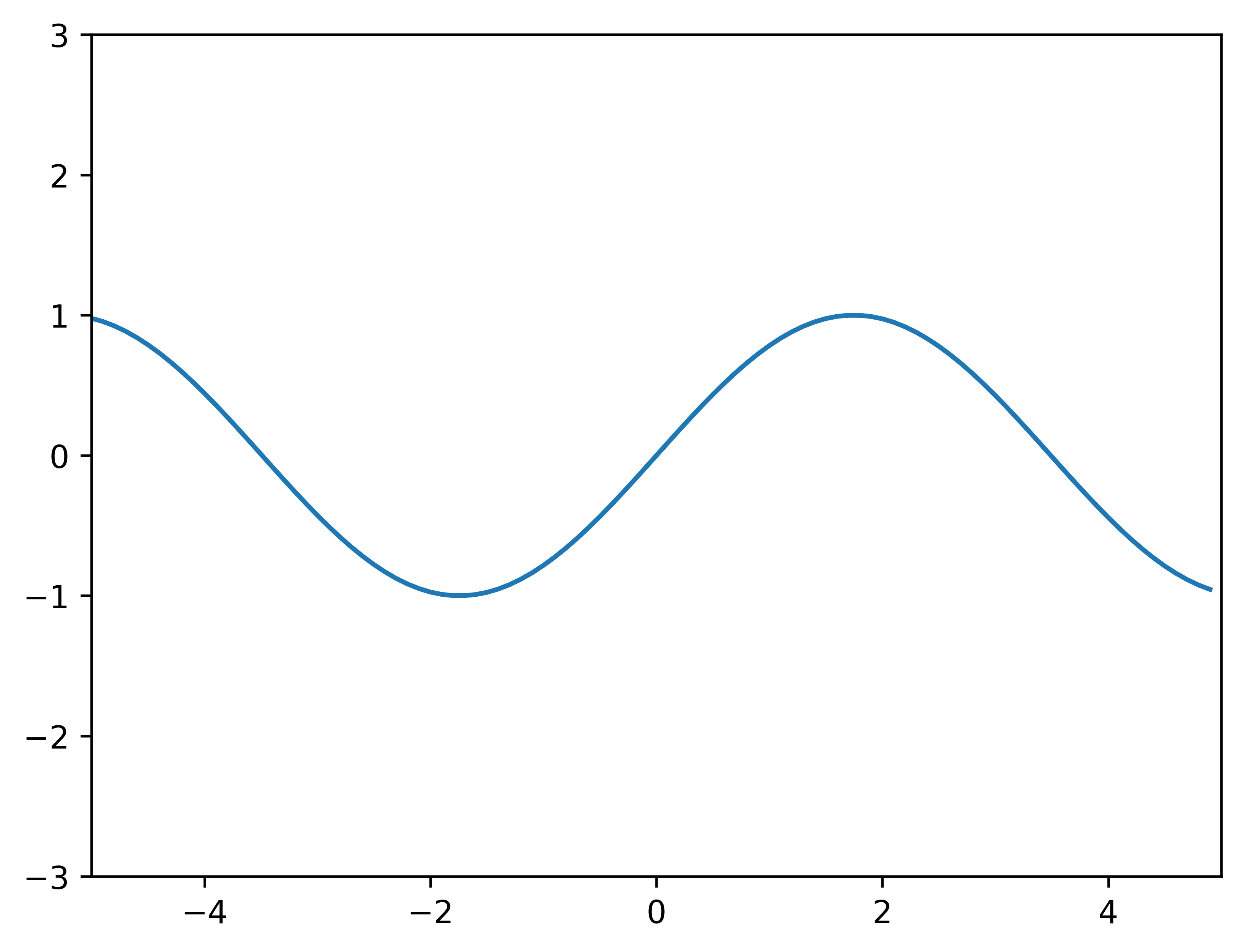
We do the regression example between -5 and 5. The observation data points (traing dataset) are generated from a uniform distribution between -5 and 5. This means any point value within the given interval [-5, 5] is equally likely to be drawn by uniform. The functions will be evaluated at n evenly spaced points between -5 and 5. We do this to show a continuous function for regression in our region of interest [-5, 5]. This is a simple example to do GP regression. It assumes a zero mean GP Prior. The code borrows heavily from Dr. Nando de Freitas’ Gaussian processes for nonlinear regression lecture.
from __future__ import divisionimport numpy as npimport matplotlib.pyplot as pltimport pandas as pd
# This is the true unknown function we are trying to approximatef =lambda x: np.sin(0.9*x).flatten()#f = lambda x: (0.25*(x**2)).flatten()x = np.arange(-5, 5, 0.1)plt.plot(x, f(x))plt.axis([-5, 5, -3, 3])plt.show()
# Define the kerneldef kernel(a, b): kernelParameter_l =0.1 kernelParameter_sigma =1.0 sqdist = np.sum(a**2,axis=1).reshape(-1,1) + np.sum(b**2,1) -2*np.dot(a, b.T)# np.sum( ,axis=1) means adding all elements columnly; .reshap(-1, 1) add one dimension to make (n,) become (n,1)return kernelParameter_sigma*np.exp(-.5* (1/kernelParameter_l) * sqdist)
We use a general Squared Exponential Kernel, also called Radial Basis Function Kernel or Gaussian Kernel:
where \(\sigma_f\) and \(l\) are hyperparameters. More information about the hyperparameters can be found after the codes.
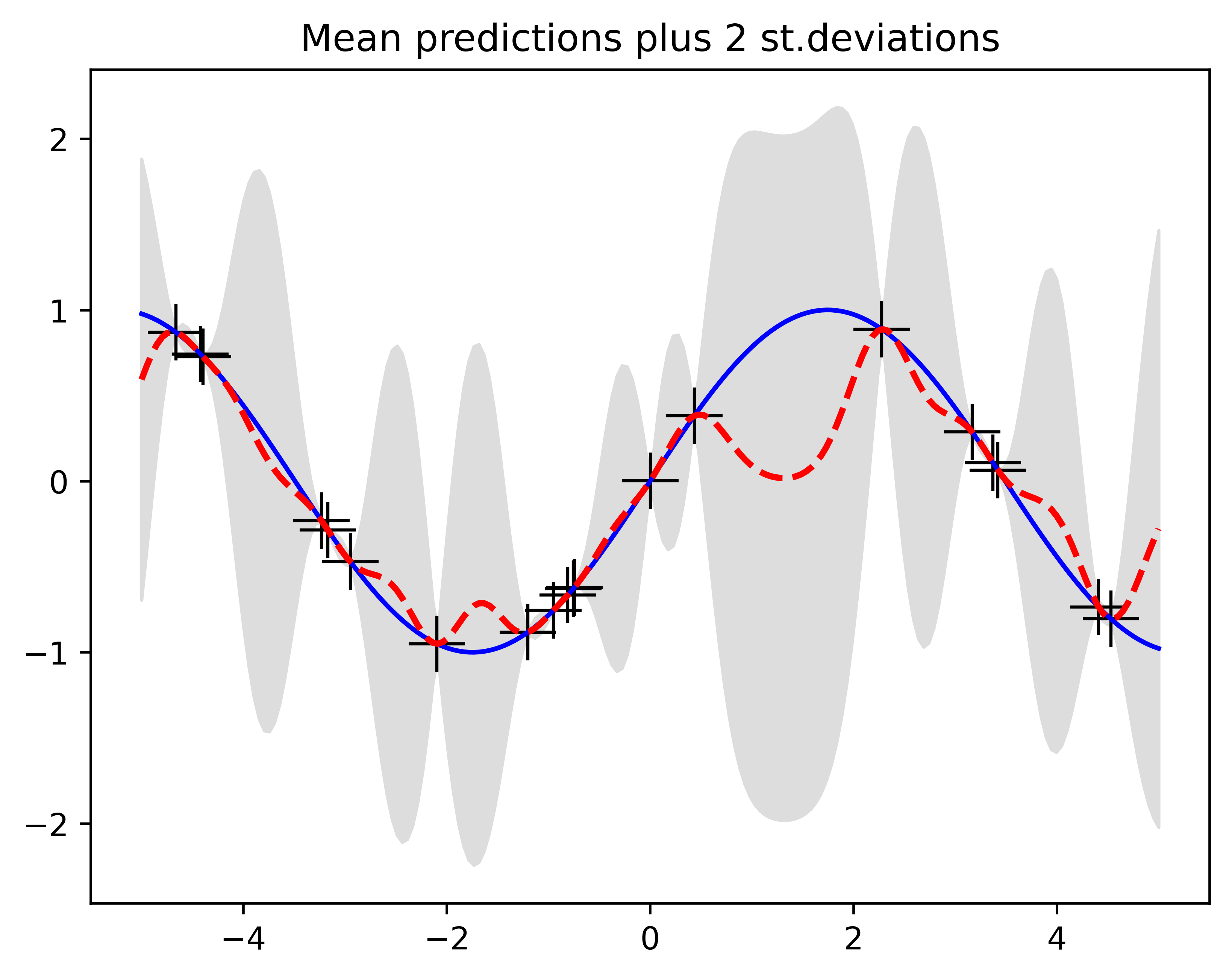
# Sample some input points and noisy versions of the function evaluated at# these points.N =20# number of existing observation points (training points).n =200# number of test points.s =0.00005# noise variance.X = np.random.uniform(-5, 5, size=(N,1)) # N training pointsy = f(X) + s*np.random.randn(N)K = kernel(X, X)L = np.linalg.cholesky(K + s*np.eye(N)) # line 1# points we're going to make predictions at.Xtest = np.linspace(-5, 5, n).reshape(-1,1)# compute the mean at our test points.Lk = np.linalg.solve(L, kernel(X, Xtest)) # k_star = kernel(X, Xtest), calculating v := l\k_starmu = np.dot(Lk.T, np.linalg.solve(L, y)) # \alpha = np.linalg.solve(L, y)# compute the variance at our test points.K_ = kernel(Xtest, Xtest) # k(x_star, x_star)s2 = np.diag(K_) - np.sum(Lk**2, axis=0)s = np.sqrt(s2)# PLOTS:plt.figure(1)plt.clf()plt.plot(X, y, 'k+', ms=18)plt.plot(Xtest, f(Xtest), 'b-')plt.gca().fill_between(Xtest.flat, mu-2*s, mu+2*s, color="#dddddd")plt.plot(Xtest, mu, 'r--', lw=2)#plt.savefig('predictive.png', bbox_inches='tight', dpi=300)plt.title('Mean predictions plus 2 st.deviations')plt.show()#plt.axis([-5, 5, -3, 3])
# draw samples from the posterior at our test points.L = np.linalg.cholesky(K_ +1e-6*np.eye(n) - np.dot(Lk.T, Lk))f_post = mu.reshape(-1,1) + np.dot(L, np.random.normal(size=(n,40))) # size=(n, m), m shown how many posteriorplt.figure(3)plt.clf()plt.figure(figsize=(18,9))plt.plot(X, y, 'k+', markersize=20, markeredgewidth=3)plt.plot(Xtest, mu, 'r--', linewidth=3)plt.plot(Xtest, f_post, linewidth=0.8)plt.title('40 samples from the GP posterior, mean prediction function and observation points')plt.show()#plt.axis([-5, 5, -3, 3])#plt.savefig('post.png', bbox_inches='tight', dpi=600)
<Figure size 3840x2880 with 0 Axes>
We plotted m=40 samples from the Gaussian Process posterior together with the mean function for prediction and the observation data points (training dataset). It’s clear all posterior functions collapse at all observation points.